[논문 리뷰] Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
Assran, Mahmoud, et al. “Self-supervised learning from images with a joint-embedding predictive architecture.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2023.
https://arxiv.org/abs/2301.08243
본 논문은 이전의 JEPA를 Image pretraining 방법인 I-JEPA로 구체화한 논문이다. Prediction target을 representation vector로 삼는다는 점에서 다른 pixel-level generation(reconstruction) 방법 대비 연산 효율성 및 few-shot learning에서 이점이 있다.
Abstract
- Hand-crafted data-augmentation에 의존하지 않는 highly semantic image representation learning 방법 소개
- 비생성적 접근 방식의 Image SSL architecture, Joint-Embedding Predictive Architecture (I-JEPA)
- Masking 전략 통한 semantic representation 생성
- 충분히 큰 scale의 target block sampling
- 충분히 informative(분산된) context block 사용
→ 경험적으로 ViT와 결합했을 때의 확장 가능성 발견
Introduction
Computer Vision 분야에는 SSL을 위한 두 접근 방식이 있다
Invariance-based methods: 같은 이미지에서 파생된 2개 이상의 augmented view에 대해 유사한 embedding 생성하도록 encoder 최적화- 높은 semantic representation 생성 가능하나 강한 bias 도입하기도 함
이미지에 적용되는 augmentation을 다른 modality(video, audio, etc.)에 적용하기 어려움
→ 위 내용은 world model을 video를 이용해 학습하겠다는 JEPA의 position paper에 기반한 내용으로 판단됨
Generative methods: MAE와 같은 reconstruction task를 수행하는 methods, Input의 일부를 제거/손상 후 예측시켜 학습Cognitive learning theory: 생물학적 시스템에서의 reprsentation learning의 주요 mechanism은 sensory input response 예측을 위해 내부 모델을 적응시키는 것 → Reconstruction 수행하는 SSL methods의 기반이 됨- Invariance-based methods 보다 적은 prior knowledge 필요로 하며 여러 modality에 폭넓게 적용 가능
- 학습된 모델의 Representation은 일반적으로 off-the-shelf evaluation (linear probing)과 제한된 supervision 전이 학습에서 Invariance-based pretraining 보다 성능 떨어짐 → 일반적으로 더 낮은 semantic representation을 가짐
Work for..
- Image transformation을 통해 추가 prior knowledge 없이 self-supervised representation의 semantic level 개선
- Abstract representation space의 missing information 예측하는 I-JEPA 도입
I-JEPA
- Pixel/token space를 예측하는 generative methods와 달리 추상적인 예측 target을 활용해 불필요한 pixel-level details 제거
Multi-block masking strategy: Informative(spatially distributed) context block을 사용해 image 내에서 충분히 큰 target 예측의 중요성 보임
Findings
- Augmented view 없이 on-the-shelf representation 학습, MAE와 같은 pixel-level reconstruction 모델보다 높은 성능 보임
- Semantic task에서 view-invariant pretraining에 준하며 저수준 vision task에서 더 나은 성능 보임 → 넓은 범위 적용 가능
- MAE, iBOT 등 methods 대비 빠른 학습 속도, 확장 가능성 보임
Background
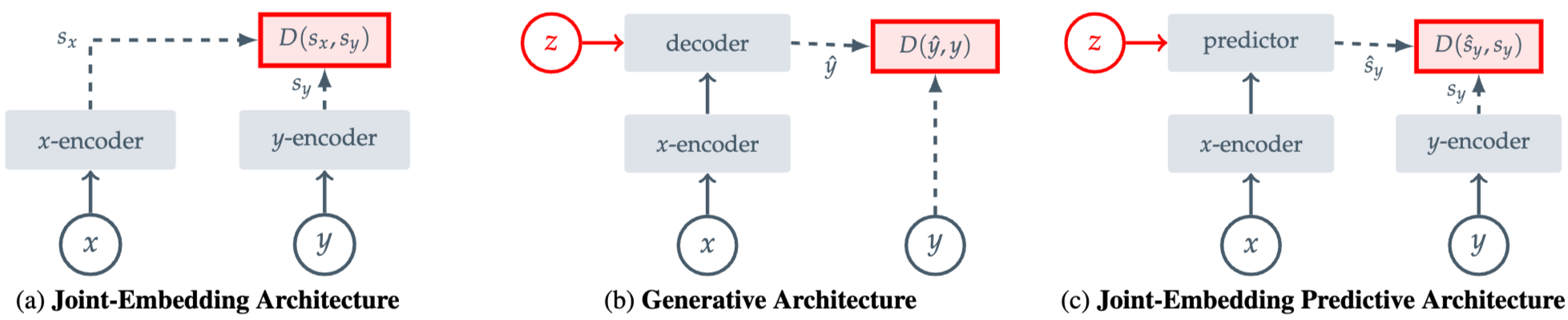
I-JEPA는 representation space에서의 prediction을 수행해 계산량을 줄여 기존 SSL 방법론보다 효율적
본 연구에서는 SSL은 input 간의 relation을 학습하는 방법이라고 언급하며 이를 Energy-Based Model (EBM) 관점으로 설명 가능하다고 함
Energy-Based Model, EBM
- label 없이 data 내부의 구조나 상관관계를 잡아내는 representation 학습
- E.g. Augmented view 간의 relation
- EBM은 input의 compatible/incompatible을 scalar 값인 enery로 평가
- Compatible(good)에는 낮은 energy, incompatible(bad)은 높은 energy → 일종의 entropy 개념
대조 loss, L2/prediction loss를 EBM 관점에서 해석 가능함
→ 위 그림의 D 를 최적화 하는 문제를 EBM 관점으로 해석
EBM의 관점?
- Observed data에는 작은 energy를, outlier에는 높은 energy 할당 ⇒ 더 stable한 상태
- Loss function의 objective를 energy와 비슷한 개념으로 보겠다는 의미
Method
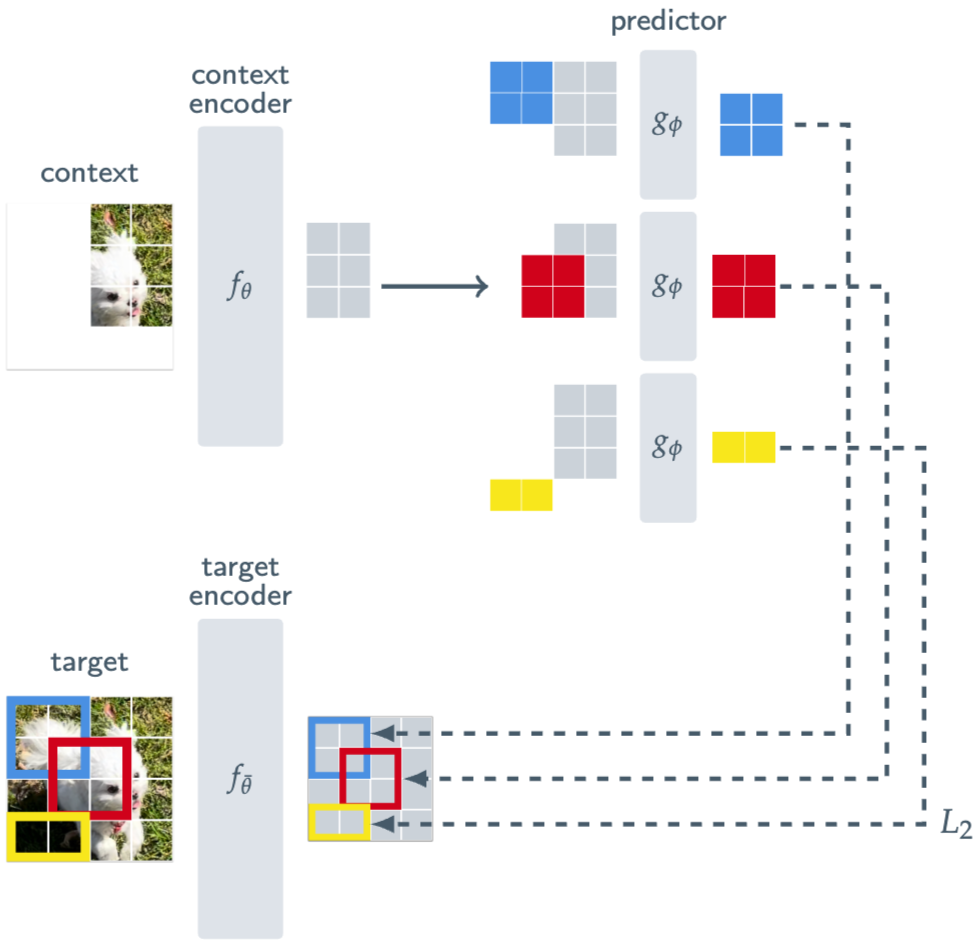
- 동일 이미지 내의 다양한 target block representation을 예측
- Encoder는 ViT 사용
- MAE와의 주요 차이점은 pixel-level이 아닌 representation-level을 예측하며 비생성적
Targets

I-JEPA의 target은** image block의 representation**이며 아래와 같이 생성된다
- Patch 분할
- Input image y에 대해 N개의 겹치지 않는 patch sequence로 변환
- Target encoder f_{\bar\theta} 통과해 patch-level representation s_y = {s_y1,…,s_{yN}} 얻음
→ 현재까지의 과정은 ViT에서 input image를 patch로 나누어 encoding 하는 것과 똑같다
- Target block sampling
- Target block은 patch sequence를 random한 scale/range로 M개 sampling
→ 앞서 만든 patch sequence를 붙여서 하나의 직사각형으로 만들어 block을 sampling한다고 생각하면 된다 Architecture 이미지를 보면 하단의 target은 4x4로 patch가 나뉘어 있는 상태이고 파랑/빨강/노랑의 세 개의 block으로 sampling되는데 이것이 target block이다
- Block은 aspect ratio range (0.75,1.5), scale range (0.15, 0.2)로 random sample
- Target block은 Context block의 예측 target
- Target mask 생성
- Sampling된 block의 index 집합을 target block mask B_i로 표현
- Mask는 이미지 상에서 적용되는 것이 아닌 encoding된 representation에 적용됨
⇒ Target block의 sampling은 모두 representation-level에서 진행되지만 각 patch의 index알 수 있으므로 Mask 생성에 patch의 index를 사용하는 것.
Context
Target block representation을 예측하기 위해 하나의 context block이 사용되며 아래와 같이 생성된다
- Context block sampling
- (0.85, 1.0) 범위의 random scale/aspect 갖는 단일 block x sampling
- Context block은 target block과 독립적으로 sampling되므로 겹침 발생 가능하므로 겹치는 영역 제거 → Target block mask 이용
- Encoding
- Context encoder를 통과해 patch-level representation s_x = {s_{x_j}}_{j\in B_x} 얻음
Prediction
- Context encoder의 representation s_x가 주어졌을 때 target block representation 예측하는 것이 목표
- Context representation과 target block의 위치에 해당하는 mask token {m_j}_{j \in B_i} 을 predictor g_{\phi}()에 입력
- Mask token은 공유되는 learnable vector와 positional embedding으로 parameterized
- Predictor는 patch-level representation \hat s_y (i) ={\hat s_{y_j}}_{j\in B_i} = g_{\phi}(s_x, {m_j}_{j\in B_i} ) 출력
Loss
- Target block representation과 predicted representation 간의 L2 distence loss 사용
- Target block의 수만큼 prediction 반복 → shared predictor
- Predictor와 context encoder는 gradient 기반으로 업데이트
- Target encoder는 context encoder의 EMA 통해 업데이트
Summary
- Target block
- Input image를 ViT와 동일하게 patch분할 후 encoding
- 직사각형 형태로 target block sampling
- Context block
- Input image에서 하나의 Context block sampling 후 target block과 겹치는 부분 제거
- Context encoder 통과
- Prediction
- Context representation과 Target block 위치에 해당하는 mask token 더해 predictor 통과
- L2 Loss 계산
Result
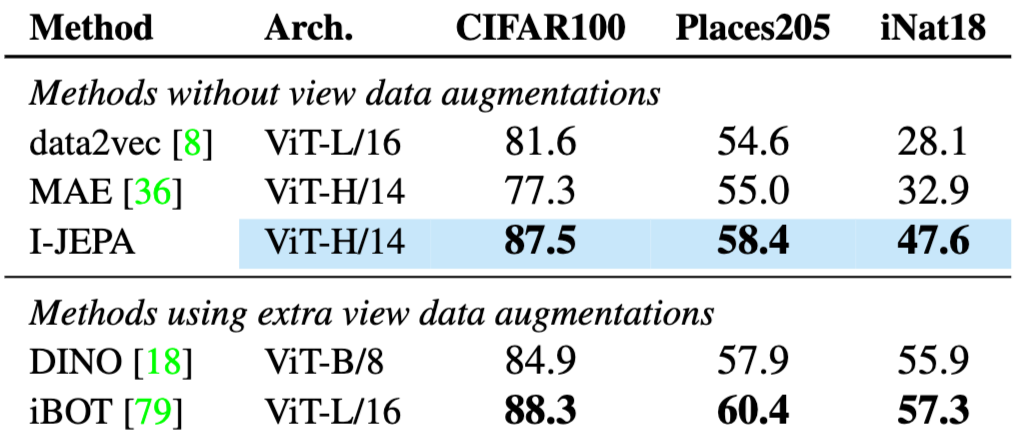
- Image classification에서의 Linear probing 성능 향상
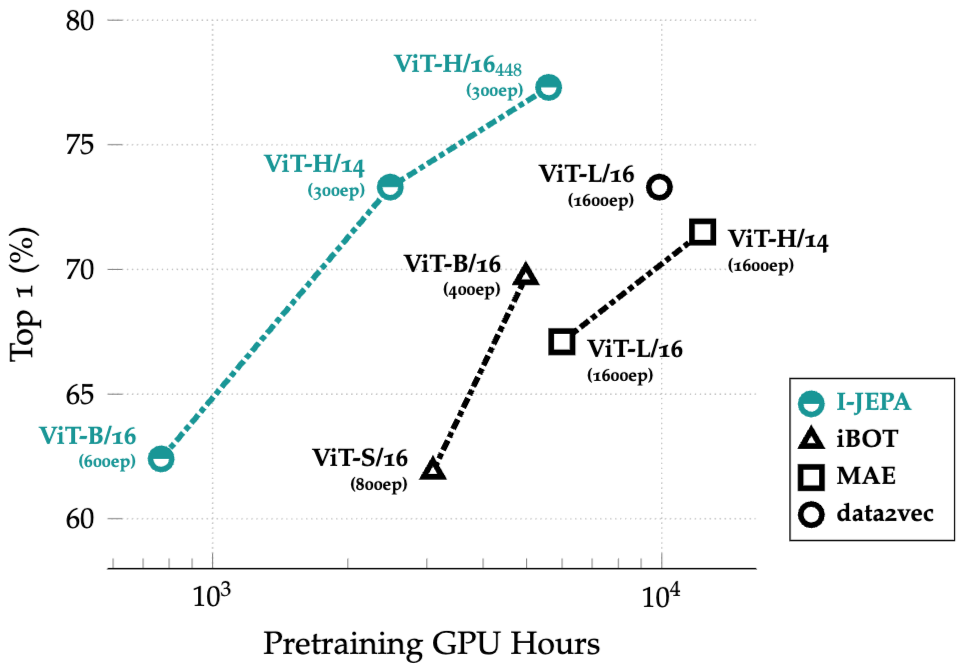
- 다른 SSL 방법과 비교했을 때 scaling 우수