[논문 리뷰] Connecting joint-embedding predictive architecture with contrastive self-supervised learning
Mo, Shentong, and Shengbang Tong. “Connecting joint-embedding predictive architecture with contrastive self-supervised learning.” Advances in neural information processing systems 37 (2024): 2348-2377.
I-JEPA의 구조적 한계로 인한 collapse를 VICReg 정규화 기법과의 결합으로 해결하려는 시도이다.
Contrastive-JEPA라는 네이밍과 달리 흔히 생각하는 InfoNCE 등의 loss를 사용하지 않고, explicit한 contrastive objective 또한 없다..?
Siamese network의 alignment와 또한 positive pair-only contrastive learning으로 보고 이러한 alignment objective 자체를 contrastive라고 표현한 듯한 느낌이다
Prediction된 representation을 eigenvalue decomposition하여 variance/covariance regularization을 적용한다는 아이디어
Abstract & Introduction
- I-JEPA의 EMA가 전체적인 collapse 예방에 비효율적
- Prediction이 patch representation의 평균을 정확히 학습하는데 부족
→ I-JEPA와 VICReg 통합한 Contrastive-JEPA 제안
Contrastive-JEPA
- Variance-Invariance-Covariance Regularization (VICReg) 원칙을 I-JEPA에 통합해 앞서 언급한 challenge 해결 목표
VICReg: variance와 covariance 학습
→ 전체적인 collapse 방지, augmented view의 평균에 대한 invariance 보장
Contribution
- I-JEPA의 내재적 한계인 EMA와 prediction mechanism을 식별하고 설명
- JEPA와 VICReg를 통합하는 C-JEPA framework 제시
- C-JEPA 성능 검증
Method
Preliminaries
Goal: Image x_i \in \R^{c\times h\times w}를 갖는 dataset \mathcal X = {x_i}^N_{i=1} 가 주어졌을 때 unsupervised representation 추출하는 f_{\theta}(\cdot) 학습I-JEPA: Self-supervised modeling를 joint-embedding predictive architecture로 간주- Context encoder f_{\theta} 와 Target encoder f’_{\theta} pair로 구성
- Predictor g_{\theta}는 Making된 target block patch {m_j}_{j\in \beta_i}와 context representation을 이용해 patch-level representation 예측
SimSiam: Contrastive SSL- 두 augmented view가 한 쌍의 network 통과
동일 image에서의 서로 다른 view 사이의 invariance 학습 위해 predictor head는 서로 다른 뷰의 representation 일치시킴
\[L_{SimSiam}=\cfrac{1}{|V|}\sum^V_{i=1}\sum_{j\in P_i}||z_{rj}-p_{rj}||^2_2\]- V : augmented view 수
- P_i : i-th view에 해당하는 모든 random patch
VICReg- Siamese 구조에서 encoder가 상수 또는 non-informative vector를 생성하는 collapse 방지 목적
- invariance term의 representation space 기반으로 variance/covariance 정규화 항 도입
- Variance regularization term : v(\mathbf{z}) = \frac{1}{d} \sum_{j=1}^{d} \max(0, \gamma - \sqrt{\mathrm{Var}(\mathbf{z}_j) + \epsilon})
Covariance regularization term : c(\mathbf{z}) = \frac{1}{d} \sum_{i \ne j} \left[ \frac{1}{n-1} \sum_{i=1}^{n} (\mathbf{z}_i - \bar{\mathbf{z}})(\mathbf{z}_i - \bar{\mathbf{z}})^T \right]_{i,j}^2
→ correlation matix C의 비대각 계수를 0에 가깝게 만들기 위해 제곱합 최소화
- \bar z = \frac{1}{n}\sum^n_{i=1}z_i
Connecting I-JEPA with SimSiam
두 방법의 유사점/차이점 명확히 하려는 목적
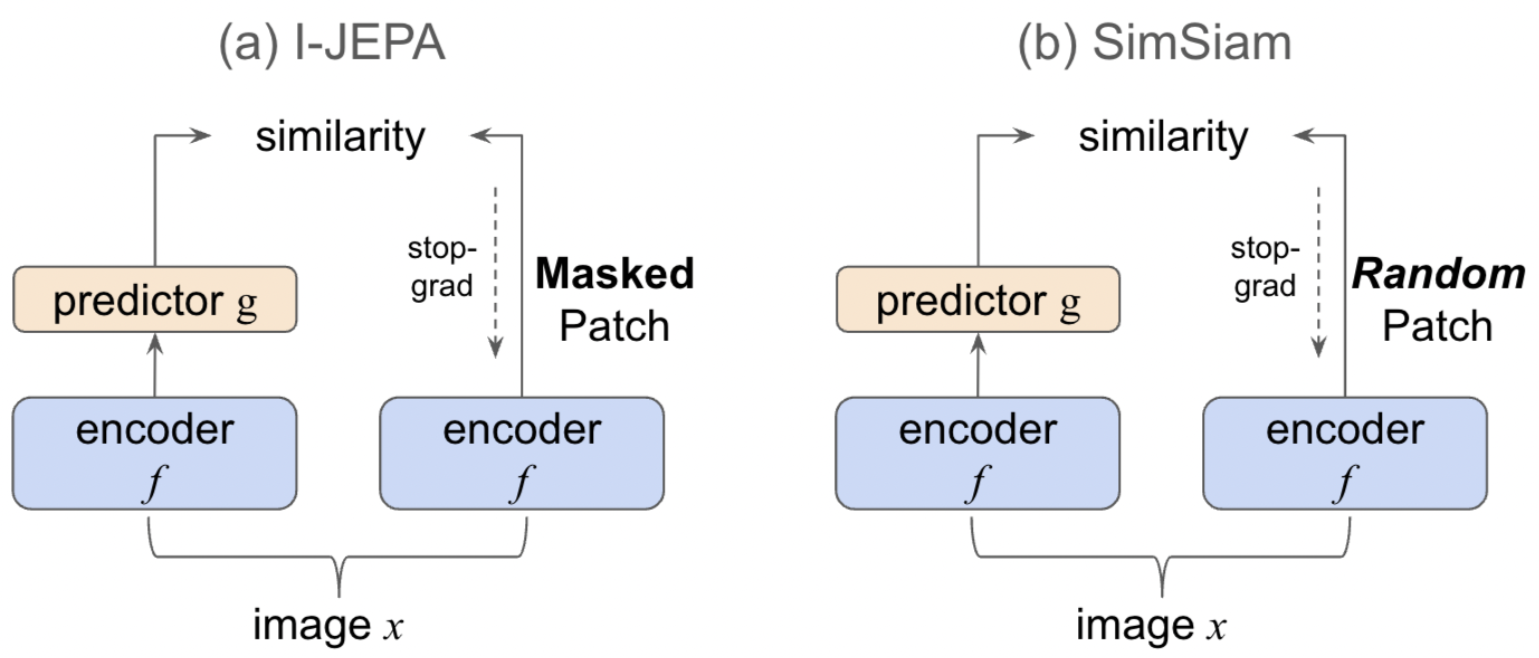
I-JEPA는 Encoder와 predictor 함께 동작해 partial view에 의존해 masking된 부분을 예측
반면, SimSiam은 명시적 masking 없이 동일 image의 augmented view를 활용해 독립적으로 처리된 view 사이의 invariance 강제
→ 두 model 모두 특정 representation 간의 distance 최소화하는 기본 원칙 공유
I-JEPA: 예측된 masked patch representation과 실제 patch representation 사이의 distanceSimSiam: augmented view 사이의 representation distance
Tian et al. 의 연구에서 BYOL/SimSiam 계열의 linear predictor가 학습 과정에서 representation의 correlation matrix에 alignment되려는 경향 보임
→ predictor가 embedding space의 eigenvectors에 맞춰 스스로를 조절 (정렬)
→ representation z를 prediction space로 옮길 때 주요 분산 방향 강조/억제하도록 동장
⇒ Predictor는 단순 무작위 weight가 아닌 data의 distribution에 맞는 linear transformation 학습
⇒ 비슷한 objective를 공유하는 I-JEPA와 SimSiam은 Predictor와 EMA/stop-grad 만으로는 collapse 발생할 수 있다
Connecting I-JEPA with VICReg
- VICReg는 Siamese network의 representation collapse를 방지하기 위해 variance/covariance regularization 도입
- VICReg를 I-JEPA와 통합함으로써 collapse에 대처하고 average representation learning 향상
→ 앞선 장에서 SimSiam과 I-JEPA의 objective 유사성 언급한 이유
⇒ 두 구조가 유사한 objective를 지니므로 VICReg라는 방식을 접목했을 때 I-JEPA또한 표현력 향상될 것이라는 전개
VICReg: covariance matrix의 비대각 요소들을 최소화하여 각 특징(eiganvalue)들이 서로 상관되지 않도록 다양성 향상→ 다양한 patch prediction이 효과적인 representation learning에 필수인 I-JEPA에 유익할 수 있음
→ VICReg의 implicit variance regularization이 representation이 similarity와 diversity 사이의 균형 유지에 도움
⇒ SSL 학습에 중요
I-JEPA의 masking objective의 linear predictor 관점 loss는 아래와 같음
\[\mathcal{L} = \frac{1}{|M|} \sum_{i=1}^{M} \sum_{j \in \mathcal{B}_i} \left\| W_P \mathbf{z}_{y_j} - \text{SG}(\mathbf{z}_{y_j}^a) \right\|_2^2\]- 예측된 patch-level representation z_{y_j}와 target representation z_{y_j}^a 간의 L2 loss
- W_p \in \R^{M\times M} : Linear predictor
- SG : Stop gradient
SimSiam과 연결을 통해 z_{y_j}의 correlation matrix를 \R:C_{z_{y_j}}=UD_CU^T 로 대각화 할 수 있음
- U : C_{z_{y_j}}의 eigenvector를 열로 하는 orthogonal matrix
D_C : Eigenvalue s_k,k \in [1,K] 의 실수 대각 행렬
→ 위 Objective 식에서의 z에 대한 correlation matrix C를 eigenvalue decomposition 한 것 (batch 내 sample들에 대한 correlation matrix)
이러한 decomposition을 고려해 predictor W_P=UD^{\alpha}_CU^T 정의
\[C_{z_{y_j}}=UD_CU^T, \space D_C=diag(s_1,...,s_k) \\ W_P=UD^{\alpha}_CU^T, \space D^{\alpha}_C=diag(s^{\alpha}_1,...,s^{\alpha}_K)\]이때 predictor matrix W_P의 eigenvalue \lambda_k=s^{\alpha}_k 가 되고 \hat z_{y_j}를 predictor의 eigenbasis representation이라고 하면 objective function은 아래와 같음
predictor matrix의 eigenvalue(eigenbasis)를 기준으로 patch representation을 표현
⇒ 원래의 representation z_{y_j}를 predictor를 대각화한 basis로 바꾼 좌표를 도입 = z를 eigenbasis로 표현한다는 의미
Experiments
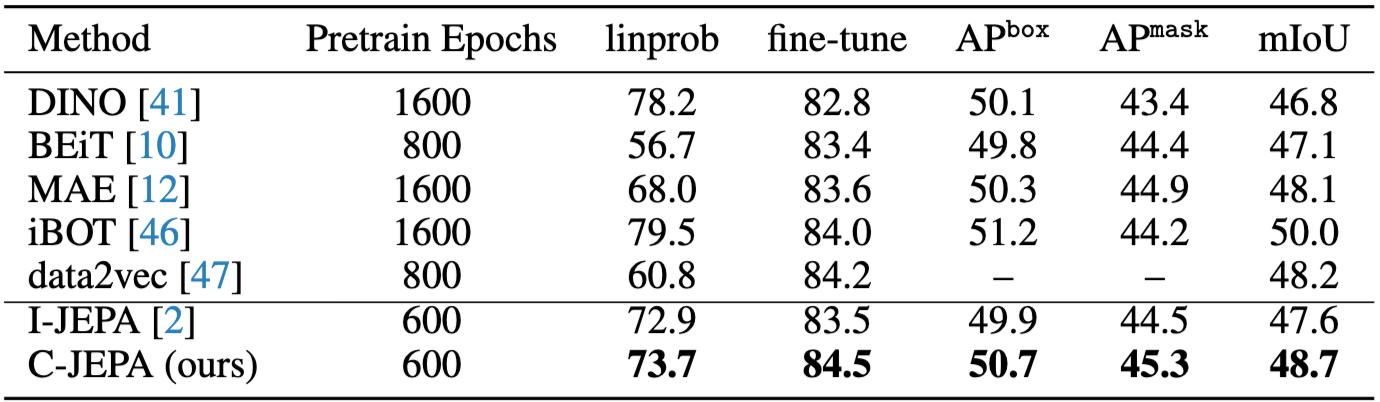
순서대로 ImageNet classification (linprob, fine-tune), COCO detection/segmentation, ADE20K semantic segmentation 결과