[논문 리뷰] A Path Towards Autonomous Machine Intelligence
이 paper는 JEPA의 개념, 학습 방법 등에 대한 아이디어를 다루는 position paper이다. 구체적인 methods가 등장하기 보다는 world model의 개념과 방향성, 그것을 구현하기 위한 JEPA와 학습 방법에 대한 고찰을 담았다
Abstract
- 자율 지능 에이전트를 구축하기 위한 아키텍처와 학습 패러다임 제시
- 구성 가능한 예측 세계 모델, 내재적 동기에 의해 구동되는 행동, 그리고 자기 지도 학습으로 훈련된 계층적 공동 임베딩 아키텍처와 같은 개념들을 결합
→ Position paper로 JEPA라는 구조의 필요성을 제기하는 paper
Introduction
- 인간과 동물은 AI/ML을 뛰어넘는 학습 능력과 이해력을 보임
- 현재의 ML 시스템은 많은 반복을 필요로 하지만 인간은 적은 노출과 경험으로 어떻게 행동할 지 학습함
- 많은 데이터 및 반복 학습에도 Real-world task에서 인간의 신뢰성에 미치지 못함
→ 해답은 World model에 있을 수 있음
AI 연구가 해결해야 할 세 가지 주요 과제 존재
- 관찰을 통해 세상을 어떻게 표현/예측/행동하는 방법을 학습할 것인가?
→ real world에서의 상호작용 없이 관찰을 통해 학습 필요
- Gradient 기반의 학습과 호환되는 방식으로 어떻게 추론/계획할 것인가?
→ 위 방식은 미분 가능한 아키텍처에서만 수행 가능하며 논리 기반의 추론과 조화롭지 않음
- Multi level의 추상화와 다양한 time scale에서 계층적인 방식으로 어떻게 인식/행동 계획을 표현할 것인가?
→ 인간과 동물은 복잡한 행동을 저수준의 행동 시퀀스로 분해, 장기적 예측/계획 수행하는 추상화 구상 가능
→ 위 과제 해결을 위해 intelligent agent 위한 아키텍처 제안, 해결법 제시
Contribution
- 모든 모듈이 미분 가능하며 많은 부분이 학습 가능한 overall cognitive architecture
- JEPA, Hierarchical JEPA : Representation의 계층을 학습하는 predictive world model을 위한 non-generative 아키텍처
- 동시에 informative/predictable representation을 생성하는 non-contrastive SSL paradigm
- H-JEPA를 불확실성 속 계층적 계획을 위한 predictive world model의 기반으로 사용하는 방법
Learning World Models
- 인간과 동물은 관찰, 과제 독립적이고 비지도적 방식으로 적은 상호작용을 통해 방대한 배경 지식 학습
- 축적된 지식은 상식으로 불리는 기초를 구성한다고 가정할 수 있음
_→ 상식은 agent에게 무엇이 가능하고 불가능한 지를 알려주는 _models of the world의 집합으로 볼 수 있음
→ 이러한 World model은 적은 시도로 새로운 기술을 배우며 행동에 대한 결과를 예측/추론/계획/탐색 가능하며 실수를 피할 수 있음
Humans and Animals learn Hierarchies of Models
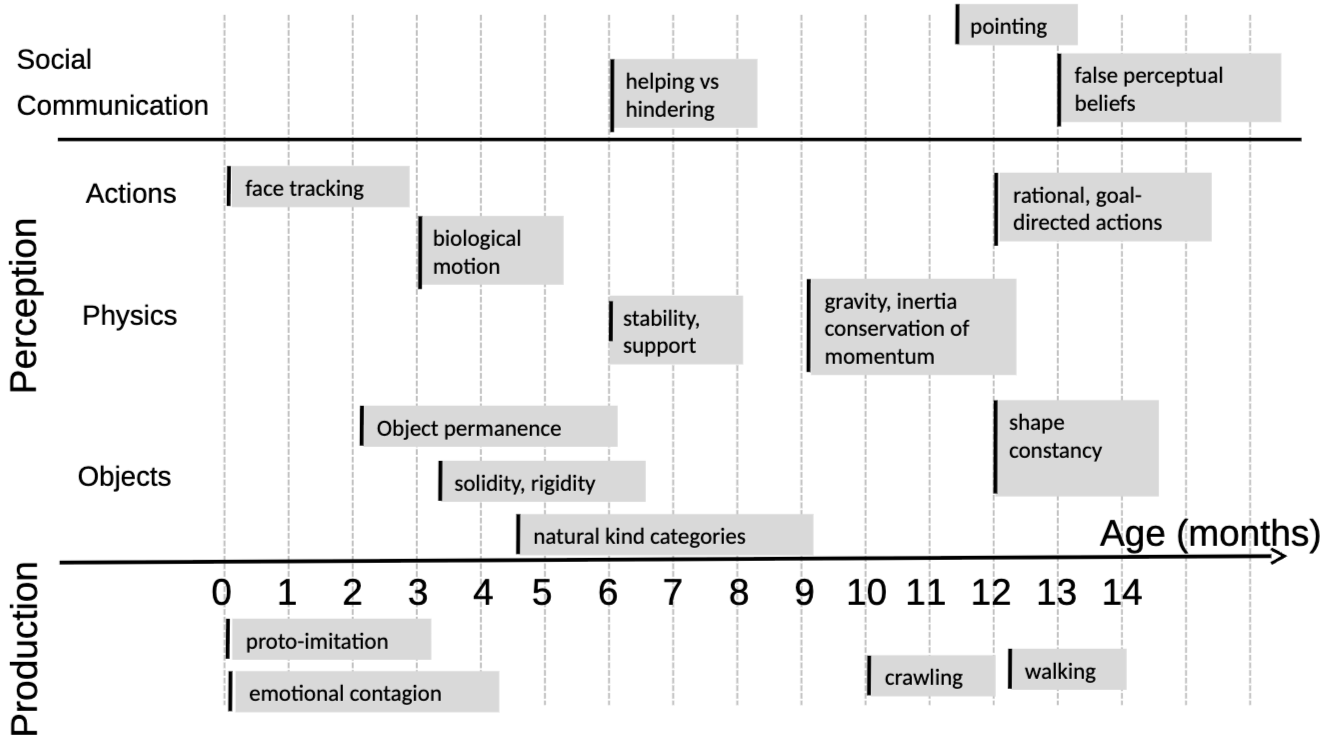
- 인간과 동물은 세상에 대한 지식을 관찰 중심으로 빠르게 쌓아가며, 이 지식은 서로 다른 추상화 수준(로컬 감각 → 객체 → 물리 법칙 → 사회적 규칙 등)으로 조직된 계층적 모델들로 구성
- 이 계층들은 하위 수준의 표현(E.g. 거리, 물체, 움직임)에 기반해 위 수준의 더 추상적 개념(E.g. 중력, 의도, 카테고리)을 학습
_→ 뇌에는 _하나의 구성 가능한(world-model engine) 엔진이 있고, 상황에 맞게 동적으로 구성되어 다양한 과제를 처리할 것이라 가정
A Model Architecture for Autonomous Intelligence
아키텍처는 여러 module로 구성되며 일부 모듈은 실시간으로 설정 가능함.
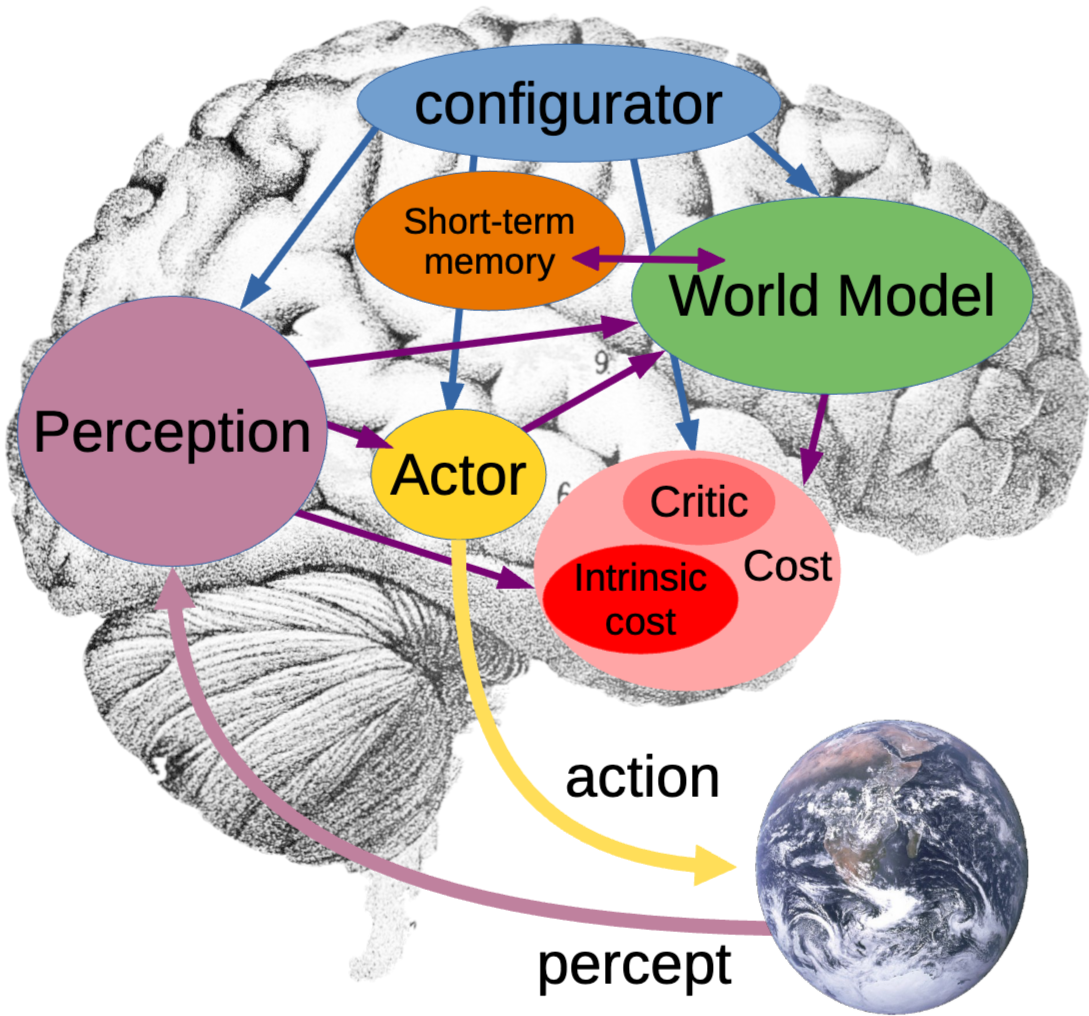
Configurator module: 다른 module로부터 입력을 받아 수행할 작업을 위해 module 구성Perception module: 현재 world의 state 추정- World state를 multiple level의 추상화 수준을 가진 계층적 상태로 표현 가능
- Configurator가 어떤 부분을 추출할 지 prime 가능
World model module: Actor가 제안한 상상 행동의 시퀀스 함수로, 미래의 world state 예측- 누락된 정보를 추정하고 미래 상태 예측
- 불확실성(다중 미래)을 표현하기 위해 latent나 확률적 표현 허용
Cost module: Agent의 discomfort 정도를 측정하는 _energy_를 단일 스칼라 값으로 계산, 두 개의 submodule로 구성- energy는 두 submodule에 의해 측정되는 term의 합으로 계산 → Agent는 energy 최소화하는 state에 머무르도록 행동
Intrinsic cost: 불변(학습 불가능)이며 현재 state의 energy 계산. 즉각적인 energy를 측정하며 기본적인 행동 동기가 됨
→ Configurator module에 의해 조절돼 다른 시간에 다른 행동을 유도할 수도 있음 = Intrinsic cost 계산 방식, 가중치를 동적으로 제어 가능
Critic: Intrinsic cost의 미래 값 예측하는 학습 가능 submodule.
Short-term memory module: 현재와 예측된 world state와 관련된 intrinsic cost 추적Actor module: 행동 시퀀스에 대한 제안 계산 → 미래 비용 최소화하는 최적의 행동 시퀀스 찾아 출력
Agent를 한 사람으로 생각하면..
- Perception : 눈/귀로 상황을 파악하는 과정
- World Model : 머릿속으로 가능한 미래를 상상하는 시뮬레이터
- Actor : 움직임을 결정해서 실제 행동으로 옮기는 의지(또는 근육 제어)
- Intrinsic Cost : 본능적 감각(통증/배고픔 등)으로 무엇이 좋고 나쁜지 판단하는 기준
- Critic : 경험으로 학습한 장기적 판단
- Configurator : 상황에 맞게 각 부분에 주의를 주고 역할을 조절 → 전두엽
- Short-term Memory : 해마
→ 개인적 판단이며 정확하지 않을 수 있음
Typical Perception-Action Loops
Model이 perception-action episode에서 사용할 수 있는 두 가지 모드 존재
Mode-1: 복잡한 추론 없이 perception의 output과 short-term memory 접근을 통해 행동Mode-2: world model과 cost 통한 추론(energy 최소화)/계획 포함
Model-1: Reactive behavior
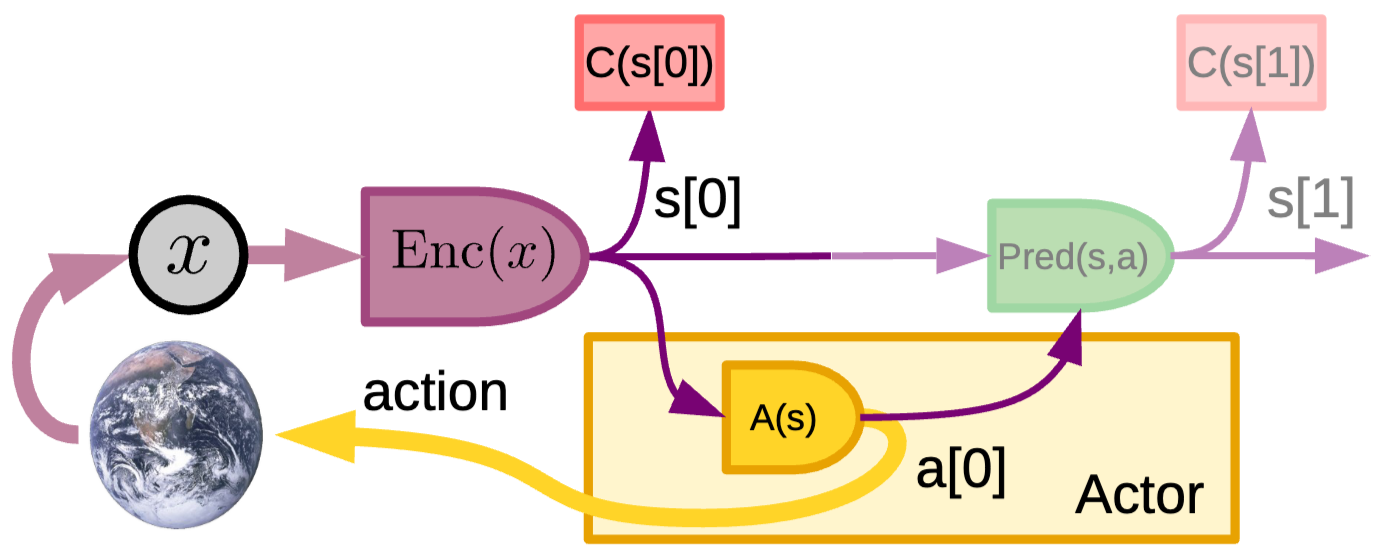
Perception module: encoder module을 통해 현재 task와 관련된 정보를 포함하는 world state의 representation s[0] 추출Policy module: Actor의 component. state function a[0] 생성, effector로 전달- a[0] = A(s[0])
- Configurator에 의해 조절
- 계획/예측 없이 순수한 reactive policy 취하지만 이전 state에 대한 완전한 정보 얻기 위해 short-term memory 사용 가능
→ 현재 world의 state(s)를 바탕으로 action(a) 결정
Cost module: 미분 가능하지만 external world model 통한 이전 action에 영향 받음- f[0] = C(s[0])
World는 미분 불가능하므로 cost ← perception ← world ← action 체익을 통해 cost로 부터 gradient 전파
→ Cost와 action 사이 미분 불가한 world로 인해 gradient 추정하므로 느리고 위험
- 선택적으로 world model을 한단계 실행해 다음 state인 s[1]을 예측한 후 percept를 기다리고 관찰된 world state를 predict target으로 사용 (Supervised update)
→ World model 사용으로 agent는 실제 시도 없이 상상으로 행동 결과를 평가하고 policy 탐색을 줄일 수 있음
Mode-2: Reasoning and planning using the world model
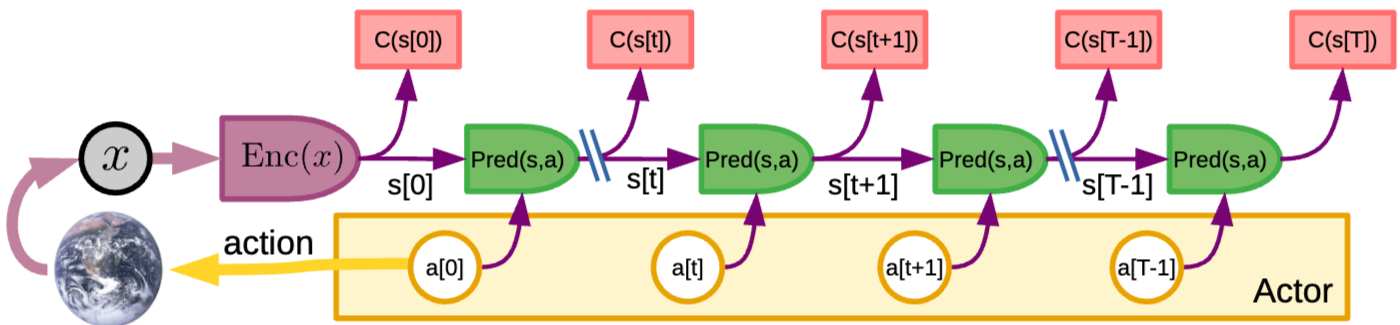
Perception: World의 현재 state s[0] = P(x) 추출, Cost module은 해당 state와 관련된 즉각적인 cost를 계산/저장Action proposal: Actor는 평가를 위한 action의 initial sequence (a[0], . . . , a[t], . . . , a[T ]) 제안
→ 계획 초안 제시, 시뮬레이션 결과 평가하도록 world model에 제안
Simulation: Action sequence로 발생할 world state representation sequence (s[1], . . . , s[t], . . . , s[T ]) 예측Evaluation: 예측된 state sequence의 cost 합 추정 (time step의 sumation으로 표현), F(x) = sum^T_{t=1}C(s[t])Planning: Actor는 더 낮은 cost 가지는 새로운 action sequence 제안- Gradient 기반 절차로 수행될 수 있음
- 전체 최적화는 2-5 단계 반복 수행 통함
Acting: Low-cost action sequence 수렴 후 첫번째 action을 effector로 전달, 전체 process는 다음 perception-action episode에 대해 반복
→ 새로운 입력(percept) 들어올 때 다시 반복 수행됨을 의미
Memory: 모든 action 후 intrinsic cost와 critic은 short-term memory에 저장, 이 pair는 나중에 critic을 train/adapt 하는 데 사용될 수 있음
위 process는 deterministic 상황을 가정한 설명이며 다양한 state, planning 접근 방식이 있을 수 있음
From Mode-2 to Mode-1: Learning New Skills
Agent는 하나의 world model engine을 가지고 있고 configurator에 의해 현재 task에 맞게 구성될 수 있으나 한번에 하나의 작업에만 사용됨
→ Mode-2를 사용하는 것에 대한 부담
Mode-1은 하나의 policy module을 통한 single pass만을 요구
→ 여러개의 policy 동시 작동 가능, 각 module은 특정 task 집합에 특화 ⇒ task에 특화된 module을 여러 작업에 병렬 수행이 가능함
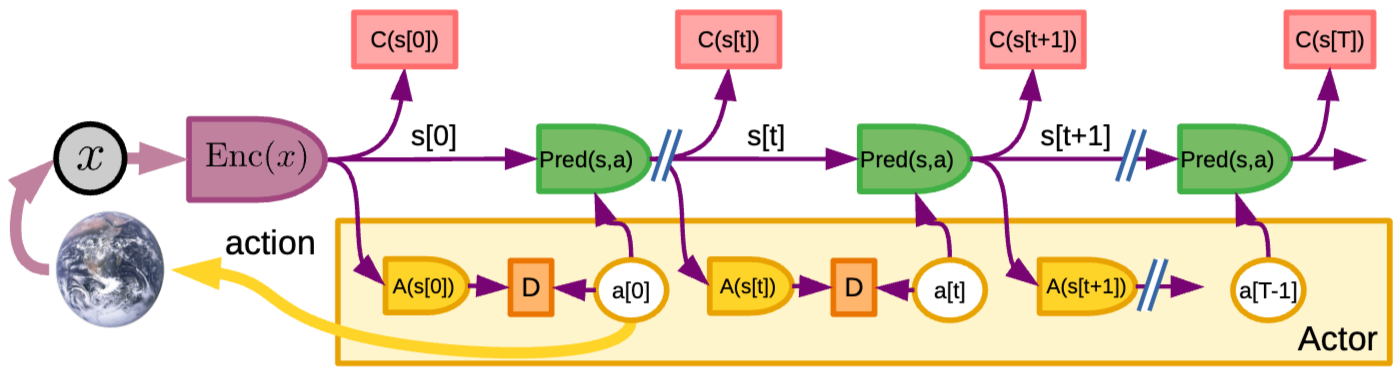
- System은 mode-2에서 실행되 optimal action sequence 생성
- policy module A의 매개변수는 해당 시점에서의 optimal action a와 policy module의 출력 간의 divergence D를 최소화 하도록 update
- 학습 후 policy module은 mode-1에서 직접 action 생성에 사용 가능 → tilde a[0] = A(s[0])
- 또한 mode-2 최적화 전 initial action sequence의 재귀적 계산에 사용
- s[t + 1] = operatorname{Pred}(s[t], a[t]) space ; space tilde{a}[t + 1] = A(s[t + 1])
- 이때 polict module은 일종의 근사 추론(amortized inference) 수행
Reasoning as Energy Minimization
- Mode-2에서 행동 시퀀스 생성 과정은 추론(reasoning)으로 볼 수 있음
- 추론은 외부 환경을 직접 탐색하지 않고 내부의 world model을 이용해 여러 가능한 미래를 시뮬레이션
- 결과에 대한 eneergy를 계산하여 optimal action을 찾는 과정
→ 행동 결정은 미래 state들의 총에너지(총비용)를 최소화하는 action sequence를 찾는 최적화 문제
The Cost Module as the Driver of Behavior
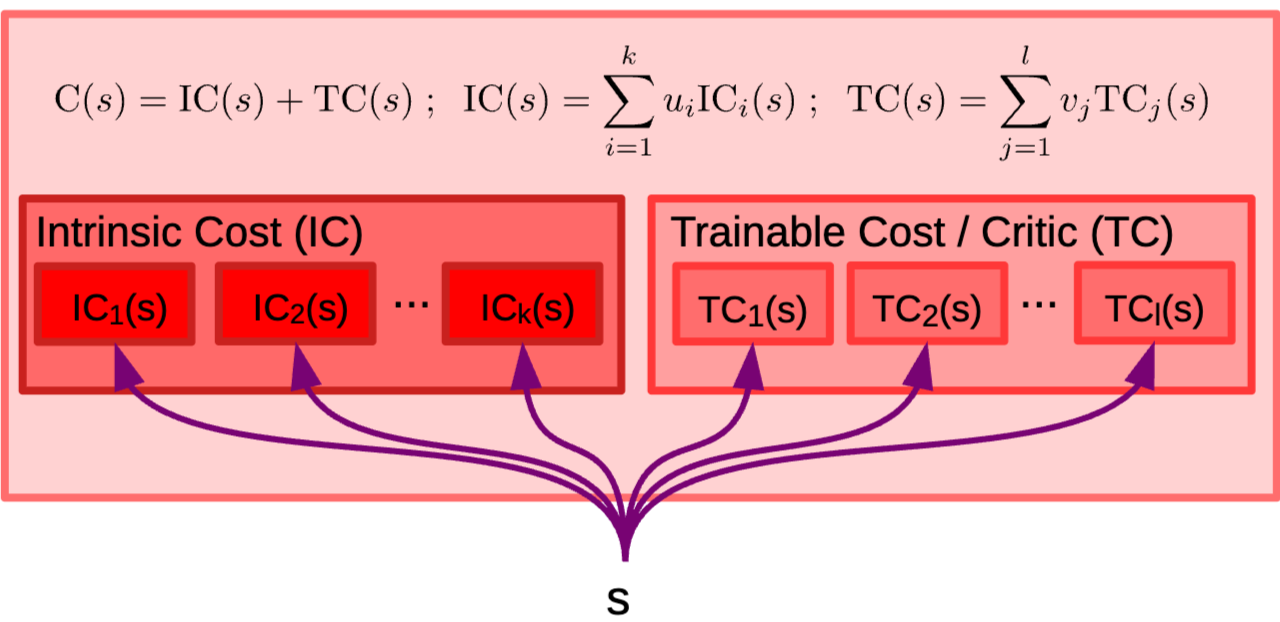
Cost module: 불변인 intrinsic cost module IC(s)와 학습 가능한 cirtic/Trainable cost TC(s)로 구성- 각 cost는 submodule들로 구성되며 이들의 output energy는 선형적으로 결합
- Submodule은 agent에 특정 행동의 동기를 부여
- weight u,v는 configurator module에 의해 조절되며 agent가 서로 다른 시점에 서로 다른 subgoal에 집중할 수 있게 함
⇒ Cost module은 agent의 action의 최종 driver로 agent는 이 cost/energy를 최소화 하기 위해 action을 수행
⇒ Cost는 즉각적인 본능적 신호(IC)와 학습된 예측값(TC)을 합쳐 계산되며 이 결합(linear combination)이 행동의 균형 결정
Training the Critic
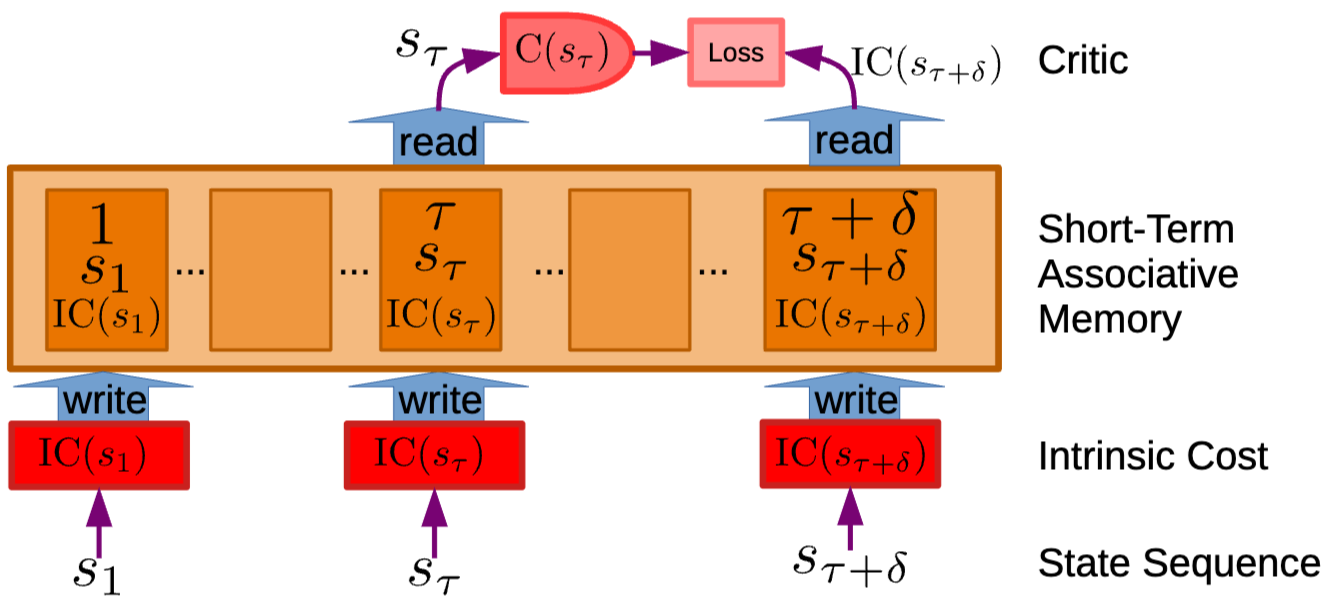
- Critic의 주요 역할은 intrinsic cost의 미래값을 예측하는 것 → 예측된 값은 Mode-2와 Mode-1 통한 policy training에 사용
- 예측을 위해 short-term memory module을 이용
- module은 agent가 경험한 time, state, IC 저장
- Planning/Action 후 이 삼중항이 memory에 기록
- Critic은 memory에서 과거 state와 이후 관측된 intrinsic energy를 가져와 predictive target으로 사용
Designing and Training the World Model
World model의 학습은 SSL의 전형적인 예시이고 기본 아이디어는 pattern completion → 미래 입력의 예측을 pattern completion의 특수한 경우로 봄
Model의 학습엔 아래 세가지 문제를 가짐
- World model의 품질은 학습 중 관찰 가능한 state sequence에 의존
- World는 완전한 예측이 불가능하기에 주어진 world state representation 뒤에 오는 여러개의 타당한 representation 존재 가능
- 서로 다른 time/abstract 수준에서의 예측 가능해야함
SSL
SSL은 Input 간의 상호의존성 학습하는 방법으로 데이터의 일부를 관찰하고 나머지가 그 관찰과 일관되는지 판단하도록 system 학습
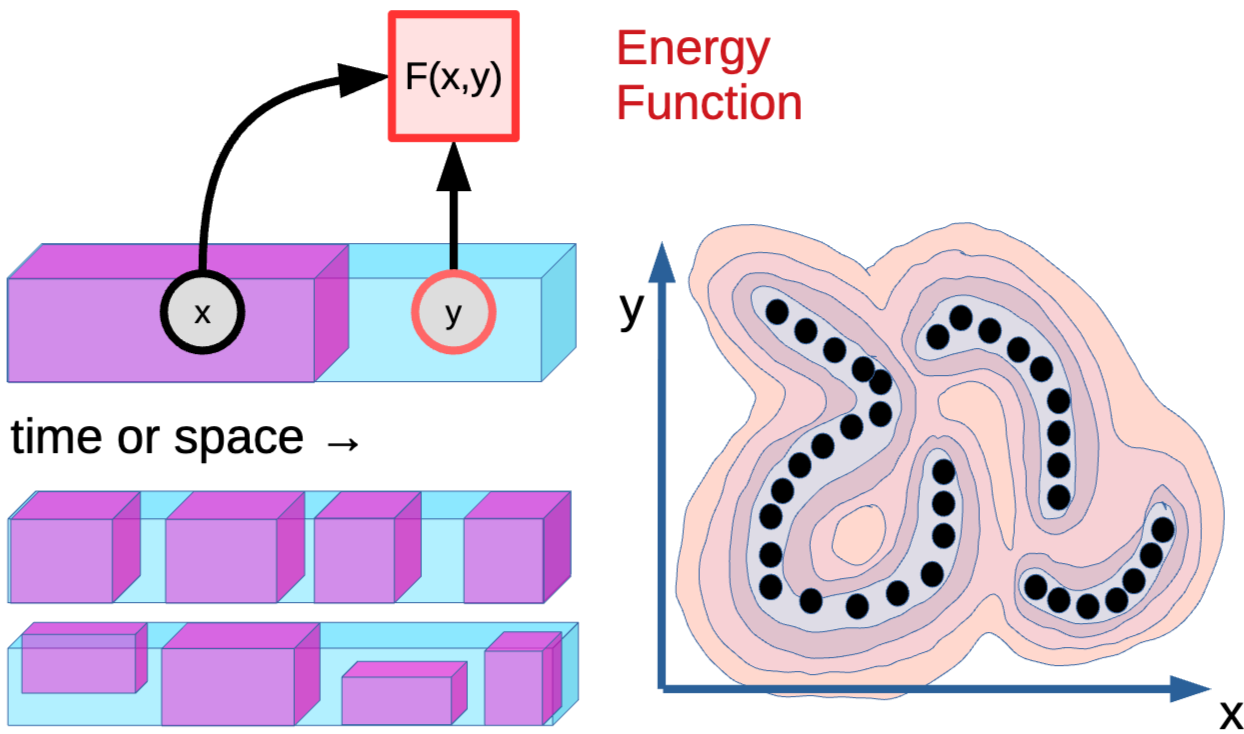
SSL을 EBM 관점으로 연결
Energy-Based Models (EBM): System은 입력 x에 따른 출력 y가 호환될 때 낮은 energy를 그렇지 않을 때 높은 값을 생성하는 Function F(x,y)- World는 x에 따른 y가 여러개 존재 가능 → Latent variable의 필요성
Latent Variables
- Model이 여러 예측을 표현할 수 있어야 함 → Latent variable를 통한 처리
Latent-variable EBM (LVEBM): 쌍 (x,y) 가 주어졌을 때 energy를 최소화하는 latent variable z 찾아 최적화- check z = underset{zinZ}{operatorname{argmin}} E_w(x,y,z)
- 이 minimization을 통해 energy function에서 z를 제외할 수 있음
Joint Embedding Predictive Architecture (JEPA)
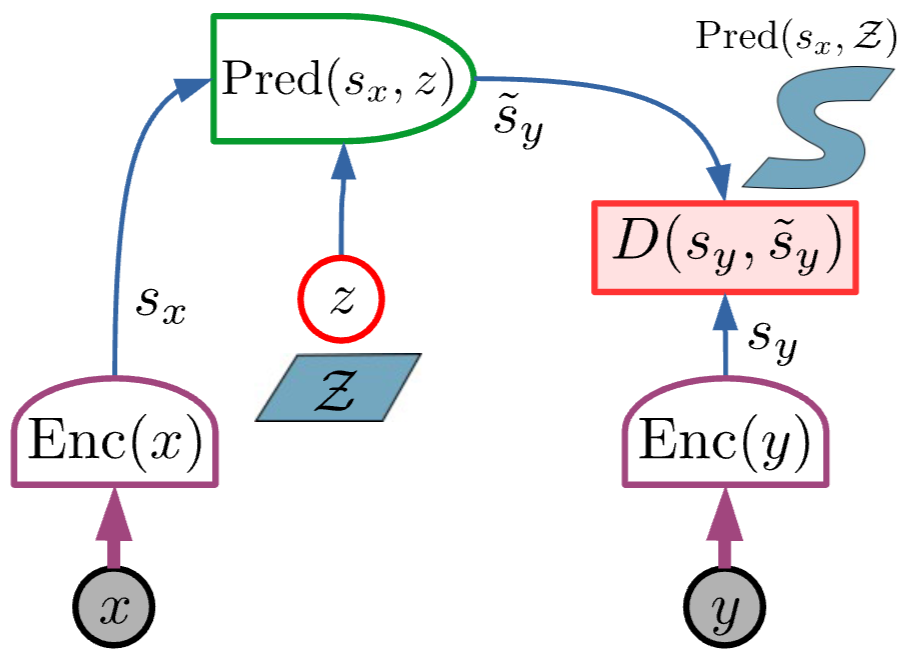
EBM 학습 과정에서의 collapse를 막기 위해 여러 architecture가 도입될 수 있으나 JEPA에 집중함
JEPA는 가능한 여러 미래값들이 입력에 대해 모두 적합할 수 있는 상황을 표현해야함 (다중성, multi-modality)
- JEPA는 x로부터 y를 쉽게 예측하는데 사용할 수 없음 → 비생성적 ⇒ 단순히 x와 y의 종속성 포착
- 두 변수 x, y는 두 개의 encoder에 입력되어 s_x,s_y 생성
- E_w(x, y, z) = D(s_y, operatorname{Pred}(s_x, z))
- 각 encoder는 다른 구조를 가져도 상관없음
→ 두 변수가 본질적으로 다를 수 있는 구조
- 전체 energy는 z를 minimizing해 얻음
- check{z} = underset{z in mathcal{Z}}{operatorname{argmin}} E_w(x, y, z) = underset{z in mathcal{Z}}{operatorname{argmin}} D(s_y, operatorname{Pred}(s_x, z)) \
F_w(x, y) = min_{z in Z} E_w(x, y, z) = D(s_y, operatorname{Pred}(s_x, check{z}))
→ 주어진 _(x,y)__에 대해 predictor가 최적의 __z__를 골라 energy를 계산_
JEPA의 장점은 representation space에서 prediction
→ y에 대한 모든 detail을 예측할 필요 없음
⇒ y의 encoder가 관련없는 detail이 제거된 abstract representation을 생성하도록 고를 수 있음 (Detail이 불필요한 noise로 작동하는 경우를 보완)
그러나 JEPA가 x에 부합하는 y값의 다중성을 나타내는 두 방법이 존재 :
- Encoder invariance : y encoder가 학습을 통해 다른 y들을 같은 코드로 매핑(invariance)
- 다른 관측값 y들이 모두 동일한 representation s_y가짐 → 동일하게 낮은 energy
⇒ 하나의 representation s_y가 y 공간을 대표해 multi-modality 표현
Pros: 불필요한 detail 제거, predictable한 중요 요소만 남김Cons: Invariance 클 경우 y 간의 구분성 사라짐 → Invariance 대한 inductive bias 중요- **Latent variable z **: z 값 선택 통해 서로 다른 s_y 생성
- energy는 최적의 z를 선택해 계산 → 다양한 y 포착 가능
Pros: encoder의 정보량을 과도하게 늘리지 않으면서도 option 선택 가능 → 복잡한 불확실성 표현 용이Cons: z의 정보량이 늘어남에 따라 collapse 위험 (z에 의존) → 정규화/제한 필요
두 방식의 상보성
- Encoder Invariance는 y의 공통된(예측가능한) 부분을 묶어 표현
- Latent variable z는 encoder가 설명 불가능한 detail(불확실한) 부분 포착
⇒ 상보적인 두 방법을 적용해 모델에 적용
Training a JEPA
모든 EBM과 마찬가지로 JEPA는 contrastive methods로 학습 가능하지만 비효율성으로 인해 non-contrastive methods 사용 (VICReg, Barlow Twins 등)
_→ _y_에 따른 _s_y_ dimension 문제를 contrastive methods의 주요 한계로 언급 (Curse of Dimensionality)_
JEPA는 non-conrtrastive methods로 학습 가능
Non-contrastive methods: low energy value를 가지는 space의 volume을 측정하는 regularizer 사용해 학습
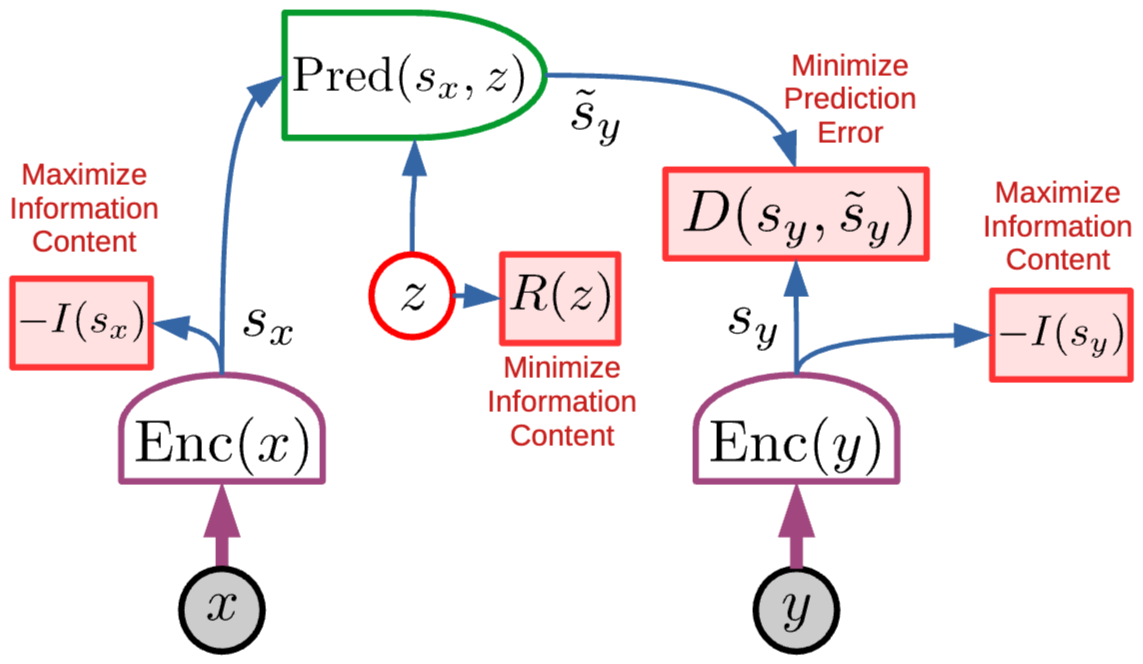
Non-contrastive JEPA 학습 기준
- s_x가 x에 대해 갖는 정보량(information content) 최대화
- s_y가 y에 대해 갖는 정보량 최대화
- s_y가 s_x로부터 쉽게 예측 가능하도록 함
- 예측에 사용되는 latent variable z의 정보량 최소화
- 기준 1, 2는 informational collapse로 인한 energy surface flatten 방지
- s_x, s_y가 입력에 대해 많은 정보량 갖도록 보장
- 기준 3은 energy term D(s_y,tilde s_y)에 의해 강제되며 representation space에서 y가 x로부터 예측 가능하다는 것을 보장
- 기준 4는 모델이 latent variable을 최소한으로 사용해 informational collapse 방지
- 기준 1, 2는 informational collapse로 인한 energy surface flatten 방지
→ 이때의 informational collapse는 대표적으로 latent variable을 copy하는 문제
→ Latent variable을 discrete, low-dimensional, sparse, noise 등으로 해결 가능
Summary
- World Model을 학습하고 활용하는 것을 목표로 새로운 architecture를 제안 (JEPA)
- High-dimensional space에서의 예측 불확실성을 다루기 위함
- 제안된 architecture의 학습을 위한 paradigm으로 non-contrastive methods 강조
긴 내용이지만 대부분 개념적이며 핵심은 world model의 architecture로 JEPA를 제안했고 non-contrastive methods가 JEPA에 효율적인 학습방법이 될 것이라는 메시지
더불어 JEPA를 video를 이용해 학습하는 것에 대한 가능성 제시