[논문 리뷰] Deep Multimodal Learning with Missing Modality: A Survey
- Multimodal train/test 에서 modality missing은 성능에 부정적
- missing modality를 처리하도록 설계된 multimodal learning은 model이 robust하게 작동할 수 있게 함
Introduction
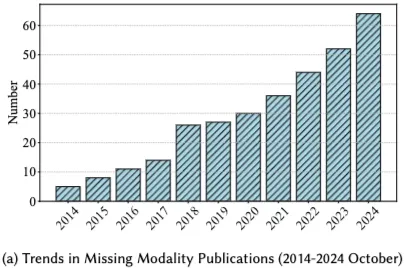
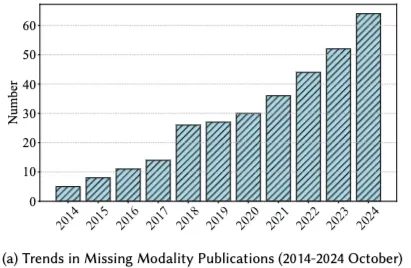
- Multimodal은 단일 modality가 감지하지 못하는 복잡한 패턴과 관계 밝힘
- 그러나 Multimodal system은 modality missing 문제에 직면하는 경우 많음 → 관심 커짐
- Missing modality가 발생하는 sample 제거는 단순하나 정보가 낭비되는 문제가 있음
→ Missing modality에도 robust하게 작동하는 system 개발이 중요
Definition
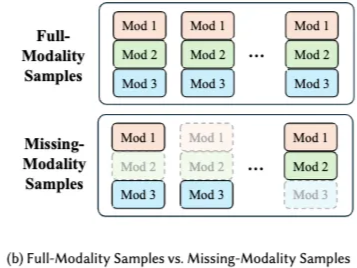
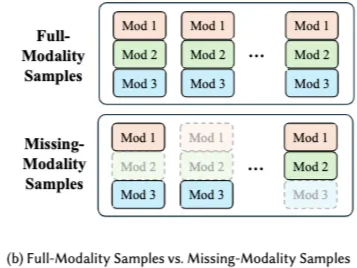
- **MLMM (Multimodal Learning with Missing Modality) **: Modality missing 문제 해결책
- MLFM (Multimodal Learning with Full Modality) : MLMM과 대조되는 모든 modality set 사용하는 방법
Challenge
- train/test 중에 사용 가능한 modality 수에 관계없이 정보를 dynamic하게 handle/fusion
- Full modality sample 성능과 유사 성능 유지
Domains
- information retrieval
- remote sensing
- robotic vision
- medical diagnosis
- sentiment analysis
- multi-view clustering
Method
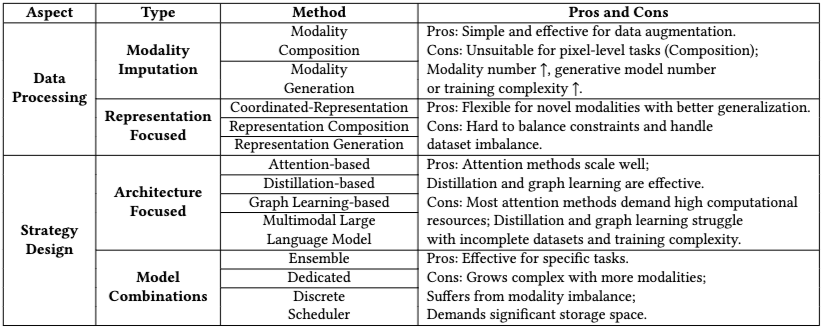
Data Processing Aspect
Model의 data processing 방법(시점)에 중점
Modality Imputation
modality data level에서 missing 처리, missing data 자체를 imputation
→ modality missing을 정확히 imputation한다면 full modality로 간주
Missing compositing : 합성
Zero/Random value composition→ dataset의 다양성 줄임
Retrieval-based composition: 유사 분류의 sample에서 데이터 copy / average (KNN)→ pixel-level task에 부적합, KNN의 경우 cost가 높고 불균형 data에 민감
Missing generating : GAN, Diffusion 통해 missing modality 생성
Individual modality generation: modality 별 생성 model 학습Unified modality generation: 전체 modality 생성 가능한 model 학습→ 고품질 생성 한계, cost 높음
Representation-Focused Models
representation level에서 missing 처리
**Coordinate representation **: 다른 modality의 representation를 semantic space에 align
RegularizationCorrelation→ 두 개 또는 세 개 modality 사용시 성능 높음
Missing compositing
Retrieval-based composition: 유사 sample의 feature 이용Arithmetic operation-based representation composition: 비학습 방식, 단순 pooling 등
Missing generating
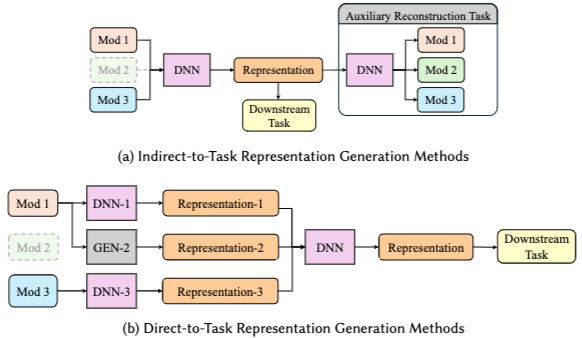
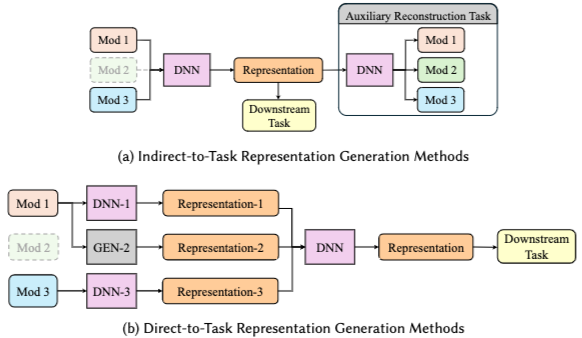
Indirect-to-task representation generation: modality 학습 시 decoder도 함께 학습, missing에 대해 decoder로 representation 생성Direct-to-task representation generation: 가용 modality의 representation으로 missing modality의 representation 생성하는 model 학습
Strategy Design Aspect
Architecture-Focused Models
train/inference 단계에서 사용 가능한 modality에 adaptive하도록 설계
Attention-based
Attention fusion: modality 내 또는 intra modality 에서의 attention fusion→ missing modality 의 정보는 실제 fusion 과정에서 무시, 존재하는 modality로 representation을 잘 만들기 위한 목적
Transformer-based
Joint representation learning: modality encoder 의 출력을 transformer 기반의 fusion model에 전달- missing modality를 masking처리
Parameter efficient learning: Full modality sample들로 학습 후 누락 modality sample들로 LoRA 등 추가해 학습
Distillation-based : full modality sample로부터의 distillation / model 내의 branch 통한 distillation
Representation-based: full modality로 학습된 teacher model로 missing modality로 학습되는 student model 지도Process-basedHybrid
→ teacher model의 학습 시 결국 full modality 요구
Graph Learning-based
- 각 modality
공통 space에 mapping - 가용 modality를 dynamic하게 연결하는
hyper edge도입 graph attention
**MLLM **: LLM이 feature processor 역할, encoder feature 통합.
Model Combinations
architecture 또는 학습 방법을 통해 해결
Ensemble : encoder 결합
Dedicated training : train method 중심
Discrete scheduler : LLM이 controller 역할을 해 task에 따라 적절한 module 선택
최근 MLMM task에 대한 연구가 늘어나고 있고 특히 의료나 비디오 등의 분야에서 주목받고 있는 듯 하다. GAN과 같은 generative model을 이용한 modality imputation 시도와 Auto encoder를 이용한 representation 단에서의 imputation이 주를 이루는 것 같다. Fusion이나 train method를 이용한 시도도 등장하고 있으나 조금 더 연구가 필요해 보인다.